Reddit Sentiment Analysis Trading Strategy


Background
Unlike traditional finance, the world of crypto is heavily directed by the community. Thus, by gaining a better quantitative understanding of how communities feel about crypto and the crypto markets, algo traders can gain an edge over other traders. In this trading algo, we will use a sentiment analysis strategy to analyze the ethereum subreddit’s headlines to make more informed trades.
Why Reddit?
It is no surprise that reddit is one of the chief areas where crypto discussions take place. There are convenient applications that allow us to easily scrape subreddits for comments and headlines, making it easy for us to perform our sentiment analysis algorithm.
What is Sentiment Analysis?
We will implement a simple algorithm using Sentiment Analysis.
Sentiment analysis is the practice of using natural language processing and computational linguistics to categorize the opinions expressed in pieces of text.
By performing sentiment analysis on posts in the ethereum subreddit, we can gain an understanding on how the crypto community feels about ethereum and trade long if the sentiment is positive.
For our algorithm, we will be using the python NLTK package to calculate polarity scores on reddit headlines. Polarity scores are measures of the negative, neutral, and positive sentiment scores of a piece of text. For example, “I love the crypto” will likely have a high positive score and a low negative score, while “Crypto prices down, investors terrified” will likely have a high negative score.
Implementation:
To create an algorithmic strategy utilizing sentiment analysis on subreddits - we need to create a reddit scraping application and instantiate an Oauth instance, then stream new headlines to our algo, then perform sentiment analysis on the headlines, then trade based on the polarity scores of our headlines.
Getting Started:
Before we continue, install the Natural Language Toolkit (NLTK) python package. For more instructions, go here: http://www.nltk.org/install.html. Open your Python command line and run nltk.download().
import praw
import asyncio
import pandas as pd
from nltk.sentiment.vader import SentimentIntensityAnalyzer as SIA
import config
from alpaca.trading.client import TradingClient
from alpaca.trading.requests import MarketOrderRequest
from alpaca.trading.enums import OrderSide, TimeInForceImport the above packages. Notice that alpaca-py follows an object-oriented approach. We will use asyncio and praw to get data from Reddit. Pandas will help us store the data and perform calculations on the data. NLTK will help us perform sentiment analysis on the stored headlines.
API_KEY = config.API_KEY
SECRET_KEY = config.SECRET_KEY
trading_client = TradingClient(API_KEY, SECRET_KEY)If you don’t yet have an alpaca account, head here: https://app.alpaca.markets/signup. Save your api key and secret key in a config.py file and initialize your alpaca-py trading client.
sia = SIA()
headlines = set()
scores = []
subr_to_asset = {
'ethereum' : 'ETH/USD'
}
subreddit = 'ethereum'
wait = 3000Finally, we initialize these values. ‘Sia’ is the initialized object for our Sentiment Intensity Analyzer. ‘Headlines’ will store the newly fetched subreddit headlines, and ‘scores’ will track the polarity scores of our headlines. ‘Subr_to_asset’ will asset in our trading algorithm, and map the subreddit to its alpaca-py asset symbol. The subreddit we will fetch from will be ‘ethereum’. Lastly, we want to run this algo every 15 min (3000s) to allow for new posts to be created, and then fetched.
Creating a Reddit Scraper:
The first step to incorporating Reddit into our algorithm is using praw to fetch subreddit headlines. How do we do this? The first step is to create a Reddit App.
Create a Reddit App:
- Log into a reddit account
- Go to https://www.reddit.com/prefs/apps/
- Click “create an app”
- Enter a name for your app - “trading” works
- Select "script"
- Use http://localhost:8080 as the redirect URI
- After clicking “create app”, you can see the app credentials. Save the Client ID and Client Secret in a config.py file.
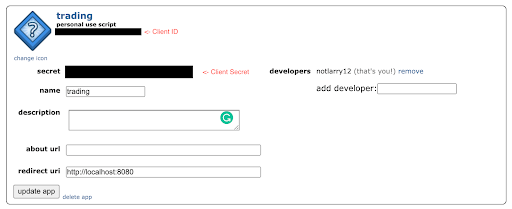
After this, let’s initialize praw in our code:
# Initialize praw to scrape reddit data
reddit = praw.Reddit(
client_id=config.CLIENT_ID,
client_secret=config.CLIENT_SECRET,
user_agent='trading by u/YOUR_REDDIT_USERNAME')We have now created a reddit app and can make requests to it by using praw! Next, let’s define our first asynchronous function, which will allow us to retrieve new headlines within the subreddit.
Working with Praw and Sentiment Analysis:
# Using reddit client, fetching new headlines within the given subreddit
async def get_headlines():
try:
for submission in reddit.subreddit(subreddit).new(limit=None):
headlines.add(submission.title)
print("got headlines")
return True
except Exception as e:
print("There was an issue scraping reddit data: {0}".format(e))
return FalseThis above code scrapes the subreddit for the newest posts and adds them to our headlines data structure, which only allows unique headlines, helping to protect against bot or double- posts.
# Scoring the polarity of each headline that we fetch
async def calculate_polarity():
try:
for line in headlines:
pol_score = sia.polarity_scores(line)
pol_score['headline'] = line
scores.append(pol_score)
print("calculated polarity")
return True
except Exception as e:
print("There was an issue calculating polarity: {}")
return TrueThis code takes the newly fetched headlines and runs the SIA model on them. This gives us polarity scores that we then store in the scores array.
Trading
# Helper function to place orders
def post_order(subreddit : str):
try:
market_order_data = MarketOrderRequest(
symbol = subr_to_asset[subreddit],
qty=0.01,
side=OrderSide.BUY,
time_in_force=TimeInForce.DAY)
market_order = trading_client.submit_order(
order_data=market_order_data)
print("Bought {}". subr_to_asset(subreddit))
return market_order
except Exception as e:
print("Issue posting order to Alpaca: {}".format(e))
return FalseWe use the above helper function to make trading easy. Notice the changes between the previous python alpaca-trade-api and the new alpaca-py module.
# Placing trades based on the polarity of our headlines
async def trade(sub : str):
mean = pd.DataFrame.from_records(scores).mean()
compound_score = mean['compound']
if compound_score > 0.05:
post_order(sub)
return TrueThis trade function takes the mean of the pandas dataframe - we take the compound score (combined negative, neutral, and positive score) and check if it’s positive or greater than the threshold. If that is true, then crypto subreddit sentiment is positive, indicating that we could take a long position on the asset.
# Setup asyncio loop
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
loop.close()At the bottom of your code, include this sequence, helping us run our code asynchronously.
Main Function
# Handle main async loop and tasks
async def main():
while True:
task1 = loop.create_task(get_headlines())
# Wait for the tasks to finish
await asyncio.wait([task1])
task2 = loop.create_task(calculate_polarity())
# Wait for the tasks to finish
await asyncio.wait([task2])
await trade(subreddit)
# # Wait for the value of waitTime between each quote request
await asyncio.sleep(wait)This is the loop of tasks that make up our algorithm - we first get new headlines, then we calculate the polarity scores, and finally trade if the conditions are favorable.
Improvements:
Congratulations - now you know how to go out and build a reddit sentiment analysis bot!
Some suggestions on improving this current algorithm:
- Better filtering for spam posts
- Adding more weight to posts that have more interaction
- Setting a certain limit to how negative the sentiment can be, even if positive sentiment is high
Good luck trading!
Source: https://www.learndatasci.com/tutorials/sentiment-analysis-reddit-headlines-pythons-nltk/
Please note that this article is for informational purposes only. The example above is for illustrative purposes only. Actual crypto prices may vary depending on the market price at that particular time. Alpaca Crypto LLC does not recommend any specific cryptocurrencies.
Cryptocurrency is highly speculative in nature, involves a high degree of risks, such as volatile market price swings, market manipulation, flash crashes, and cybersecurity risks. Cryptocurrency is not regulated or is lightly regulated in most countries. Cryptocurrency trading can lead to large, immediate and permanent loss of financial value. You should have appropriate knowledge and experience before engaging in cryptocurrency trading. For additional information please click here.
Cryptocurrency services are made available by Alpaca Crypto LLC ("Alpaca Crypto"), a FinCEN registered money services business (NMLS # 2160858), and a wholly-owned subsidiary of AlpacaDB, Inc. Alpaca Crypto is not a member of SIPC or FINRA. Cryptocurrencies are not stocks and your cryptocurrency investments are not protected by either FDIC or SIPC. Please see the Disclosure Library for more information.
This is not an offer, solicitation of an offer, or advice to buy or sell cryptocurrencies, or open a cryptocurrency account in any jurisdiction where Alpaca Crypto is not registered or licensed, as applicable.









{kind=link}