So you have written your first algorithm using the Alpaca API. Now, you want to test it. Let it run against future data. While you do that, you want to use your time to develop another idea you might have. But Alpaca only supports one websocket connection at a time. That means you cannot simultaneously get a data stream for more than one algorithm instance. One solution would be to open more accounts, the other is to keep reading ;)
For that purpose I have created the Alpaca Proxy Agent.
 shlomikushchi
shlomikushchi
This first article will give you a very brief explanation on how to use the proxy agent. Therefore, if you want, you could use it without going too deep into the technical details so you could focus on your algorithm logic and not on the infrastructure you use.
I will go into more detailed explanation in the next articles, for those who want to understand how it works and maybe even enhance its functionality.
What is the Alpaca Proxy Agent
Alpaca allows a user to open one websocket, but has much more flexible limits on the data streamed on top of that websocket. In other words, you can get data for multiple algorithms using the same websocket connection.
So in theory we could do something as described in this simplified diagram:
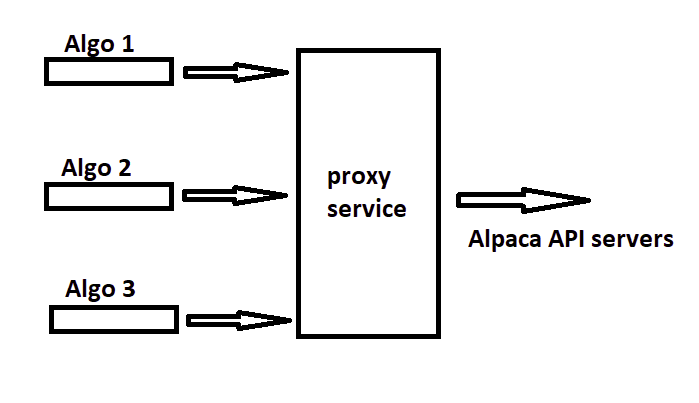
You run the proxy server locally, and the algorithms are using the local network interface to communicate with it.
Working with Docker
I assume you have docker installed.

You don’t need to be a docker expert to work with this project. You just need the basic understanding of it, and make sure it’s installed properly.
The reasons I chose to use docker are
- Make it as simple as the users choose it to be, to work with. If the users want to understand the internals of the project and run it in an IDE using breakpoints or changing the code - they can. If they want to just use a command line interface and use it with a simple one-liner, it’s possible too.
- Releasing new versions is very simple using the integration with dockerhub
- Make it language agnostic. Alpaca provides many SDKs to their API (python, js, GO, C#). This project is written in python using the python SDK, but it does not matter to the user. You could write your algorithm with any language you choose. Using docker, hides the internal implementation from you. You don’t even need to install python locally, if you don’t want to (but you should, cause it’s awesome :) )
alpacahq
Running Locally
To execute the alpaca proxy server locally you should:
- Pull the latest docker image from dockerhub (you should always do this to make sure you have the latest changes):
docker pull shlomik/alpaca-proxy-agent- Choose the data stream source you work with (Alpaca supports 2 data sources: its own, and polygon for funded accounts)
Run this to work with the Alpaca data stream:
docker run -p 8765:8765 -e USE_POLYGON=false shlomik/alpaca-proxy-agentAlternatively run this to work with the Polygon data stream:
docker run -p 8765:8765 -e USE_POLYGON=true shlomik/alpaca-proxy-agentExplanation:
- -p: which local port you expose to the algorithm. You could basically choose whatever you want. E.g:
-p 12345:8765 or -p XXXX:8765- -e USE_POLYGON as explained, you specify your selected data source here.
And That’s pretty much that.
Connecting Your Algo
Now, once it’s running locally you need to configure your algorithm to connect its websocket to the proxy agent and not directly to the Alpaca servers. The proxy agent will do that for you.
First figure out how docker executes your containers.
Is it on localhost (127.0.0.1) ? Are you using a docker machine? Is it inside a virtual box (192.168.99.100)? Do a quick google search to figure that out if you don’t know (something like “docker - what is my container URL?” will do the trick)
Each SDK has its own way to connect to the API and it’s documented in the SDKs docs.
For instance in the python SDK you could pass the data URL to the websocket instance, or you could define it in an environment variable and the SDK will read it from there.
For instance if you use the python SDK you could do this:
conn = StreamConn(
ALPACA_API_KEY,
ALPACA_SECRET_KEY,
base_url=URL('https://paper-api.alpaca.markets'),
data_url=URL('http://192.168.99.100:8765') # <=== the docker url goes here
)By doing that, you told the StreamConn instance to connect to the local docker container that runs the proxy server.
The next you need is to set an environment variable called `DATA_PROXY_WS` used by internal parts of the sdks.
doing something like this, will do:
export DATA_PROXY_WS="ws://192.168.99.100:8765"
or
export DATA_PROXY_WS="ws://127.0.0.1:8765"
==> decided by your container url
(if you use a windows machine change export to set)From this point on, you work exactly as you worked before. It’s as simple as that.
As I mentioned, this is going to be a very brief introduction to the project, without going into details of implementation.
In the next articles I will:
- Explain what is going on inside.
- Show how to work with it using projects like Pylivetrader and Backtrader
alpacahqalpacahqAgain the project discussed today can be found in the following GitHub repository.
shlomikushchiFollow @AlpacaHQ on Twitter!
Brokerage services are provided by Alpaca Securities LLC ("Alpaca"), memberFINRA/SIPC, a wholly-owned subsidiary of AlpacaDB, Inc. Technology and services are offered by AlpacaDB, Inc.





