
Please note that this article is for educational and informational purposes only All screenshots are for illustrative purposes only. The views and opinions expressed are those of the author and do not reflect or represent the views and opinions of Alpaca. Alpaca does not recommend any specific securities or investment strategies.
This article first appeared on Medium, written by Bruce Yang, Jingyang Rui, and Xiao-Yang Liu.
Paper trading is a MUST for algorithmic trading especially for machine learning trading strategies. Most fund would test and fine-tune their strategies through paper trading before shooting real trades.
In quantitative finance, stock trading is essentially making dynamic decisions, namely to decide where to trade, at what price, and what quantity over a highly stochastic and complex stock market. As a result, Deep Reinforcement Learning (DRL) provides useful toolkits for stock trading. Taking many complex financial factors into account, DRL trading agents build a multi-factor model and provide algorithmic trading strategies, which are difficult for human traders.
In this article, we use a single Jupyter notebook to show all the steps for paper trading to test our DRL strategy in real life!
After reading this article you will be able to
- Train a DRL agent on minute level data of Dow 30
- Deploy the DRL agent to Alpaca trading API using FinRL
- Place trades on Alpaca using virtual money through Jupyter Notebook
What is Paper Trading?
Paper trading is simulated trading that allows people to 1) practice trading securities; 2) test and fine-tune new investment strategies before apply it in live account; 3) teach beginners how to place orders and learn the trading basics.
However, paper trading does not 1) reflect true emotions in live trading; 2) deal with risk aversion; 3) represent real spreads because it’s virtual money not real money.
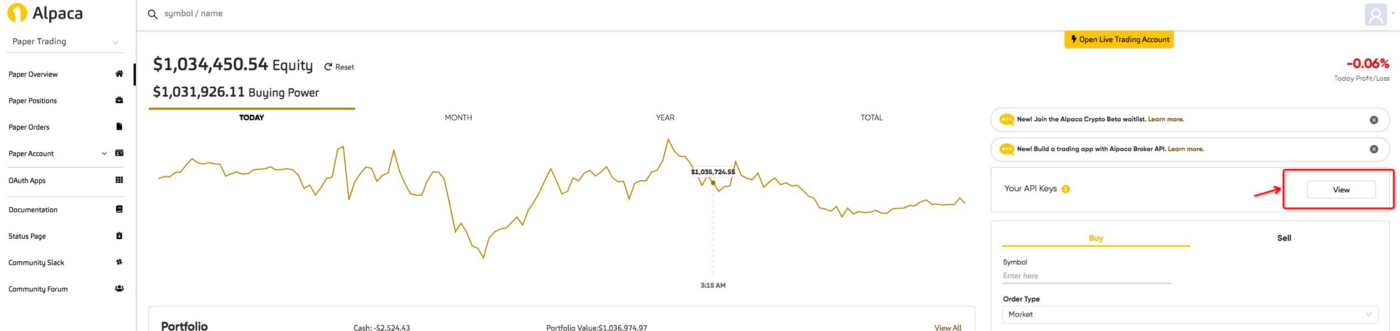
Part 1: Setup Alpaca Paper Trading API
We select Alpaca Trading API mostly because it’s free and beginner friendly.
1.1 Key Advantages:
- Commission-free like Robinhood
- Easy to use, good interface
- Good API for algo-trading, beginner friendly
- Unlimited testing of the strategies and bots for free
- No need to be a US resident
The free rate limit is 200 requests every minute per API key.
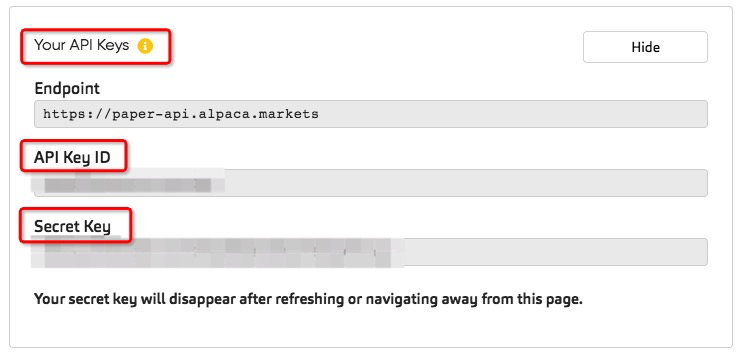
1.2 API Endpoints Setup
In Alpaca’s documentation, you’ll find all the API calls to submit trades, check the portfolio, and utilizing Python. Here are some good blogs that have very detailed introduction.
To get started in this article, you only need to 1) register an account, 2) generate and keep your API Key ID & Secret ID (need to regenerate key if forget).

Part 2: Get our Deep Reinforcement Learning Agent Ready!
2.0 Install FinRL
FinRL is an open-source framework to help practitioners establish the development pipeline of trading strategies based on deep reinforcement learning (DRL). The FinRL framework allows users to plug in and play with standard DRL algorithms. Please refer to this blog for FinRL installation. This blog uses Google Colab to run Jupyter notebook, please find our code here:
 AI4Finance-Foundation
AI4Finance-Foundation2.1 Training-Testing-Trading Pipeline
The “training-testing” workflow used by conventional machine learning methods falls short for financial tasks. It splits the data into training set and testing set. On the training data, users select features and tune parameters (k-folds); then make inference on the testing data. However, financial tasks will experience a simulation-to-reality gap between the testing performance and real-live market performance. Because the testing here is offline backtesting, while the users’ goal is to place orders in a real-world market.
FinRL employs a “training-testing-trading” pipeline to reduce the simulation-to-reality gap.
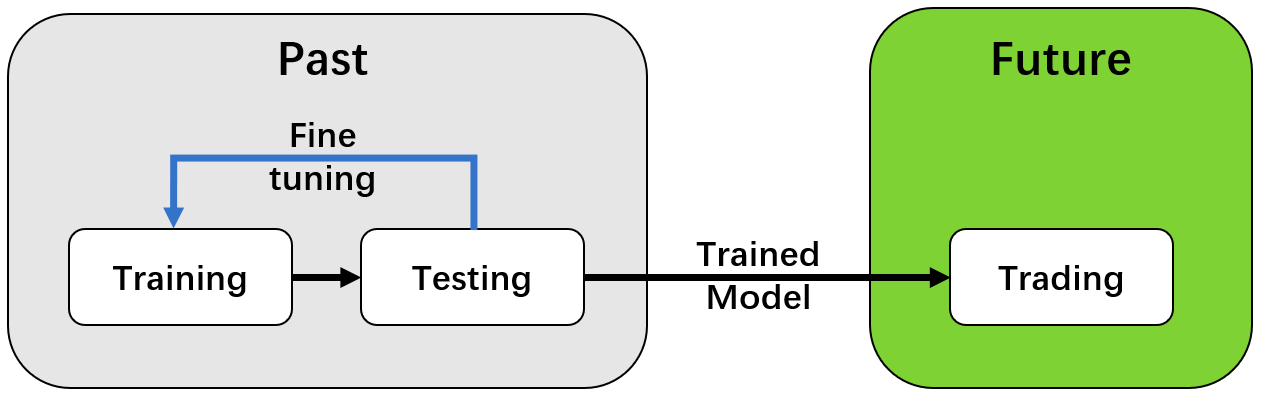
We use historical data (time series) for the “training-testing” part, which is the same as conventional machine learning tasks, and this testing period is for backtesting purpose. For the “trading” part, we use live trading APIs, in this case is Alpaca, allowing users carry out trades directly in a trading system.
2.2 Data Engineering
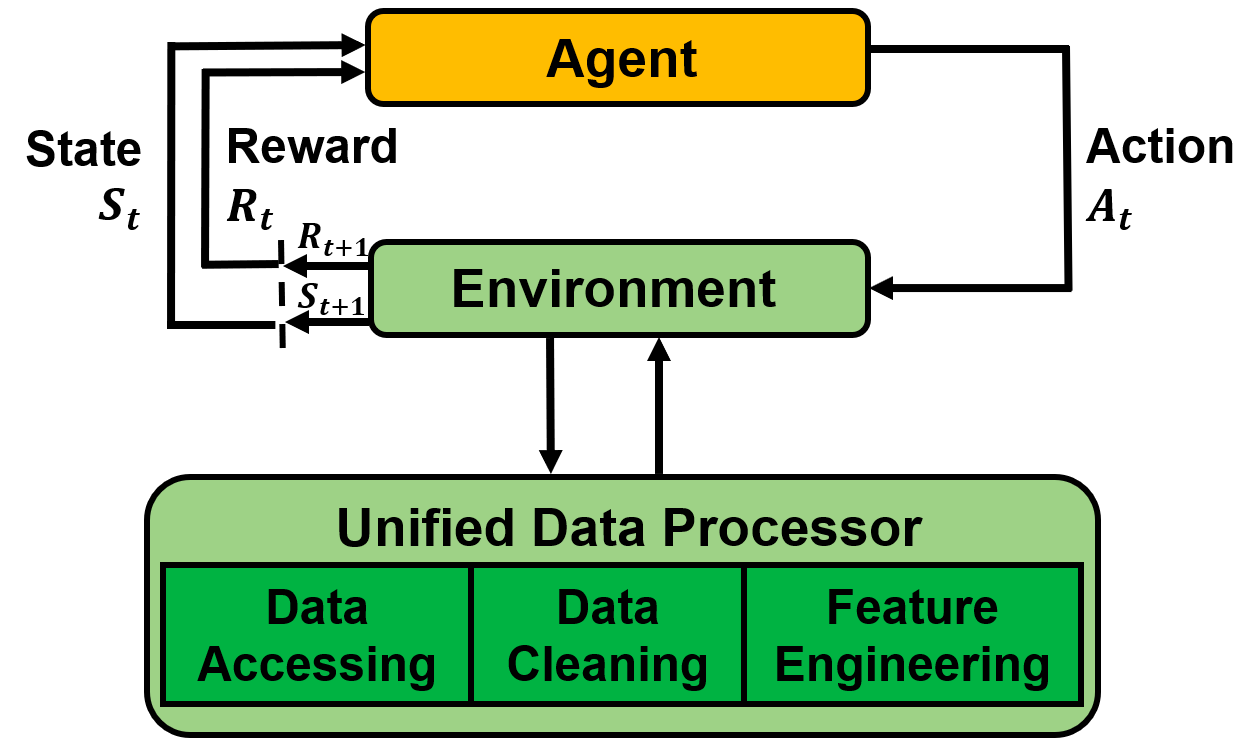
We establish a standard pipeline for financial data engineering in RL, ensuring data of different formats from different sources can be incorporated in a unified framework. Then, we automate this pipeline with a data processor, which can access data, clean data, and extract features from various data sources with high quality and efficiency. Our data layer provides agility to model deployment.
Step 1: Pick a data source
DP = DataProcessor(data_source = 'alpaca',
API_KEY = API_KEY,
API_SECRET = API_SECRET,
APCA_API_BASE_URL = APCA_API_BASE_URL)Step 2: Get the stock ticker list, set start/end date, and specify the time_interval
data = DP.download_data(start_date = '2021-10-01',
end_date = '2021-10-05',
ticker_list = ticker_list,
time_interval= '1Min')Step 3: Data Cleaning & Feature Engineering
data = DP.clean_data(data)
data = DP.add_technical_indicator(data, TECHNICAL_INDICATORS_LIST)
data = DP.add_vix(data)Step 4: Transform to numpy array format
price_array, tech_array, turbulence_array = DP.df_to_array(data, if_vix='True')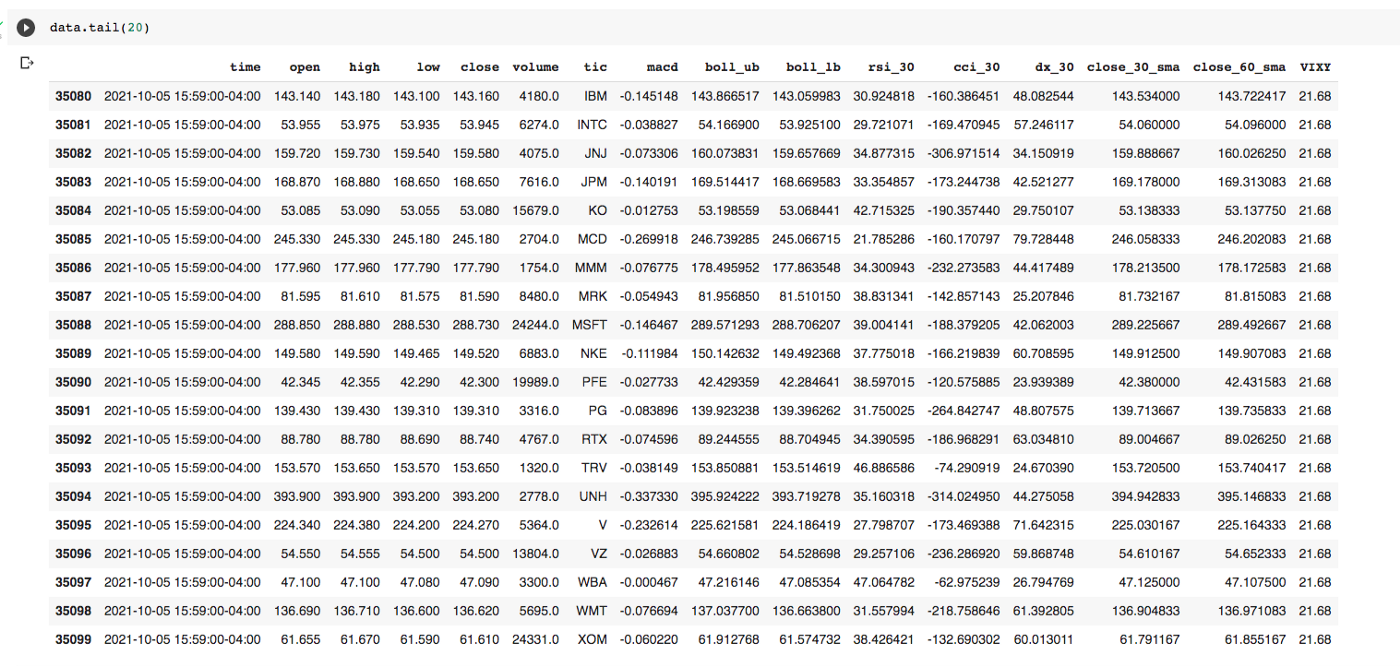
2.3 Train our DRL agent
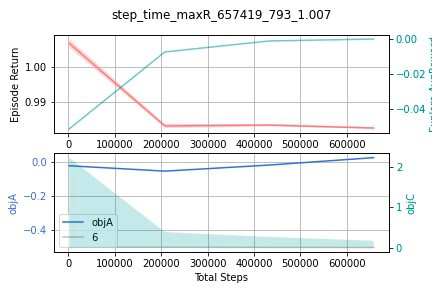
We only need to provide some basic parameters and model hyperparameters to the train() function, after training finished, it will output the trained model to the folder we specified (cwd) along with the learning rate plot.
#demo for elegantrl
ERL_PARAMS = {"learning_rate": 3e-5,
"batch_size": 2048,
"gamma": 0.99,
"seed":312,
"net_dimension":512}
train(start_date = '2021-10-11',
end_date = '2021-10-15',
ticker_list = ticker_list,
data_source = 'alpaca',
time_interval= '1Min',
technical_indicator_list= TECHNICAL_INDICATORS_LIST,
drl_lib='elegantrl',
env=env,
model_name='ppo',
API_KEY = API_KEY,
API_SECRET = API_SECRET,
APCA_API_BASE_URL = APCA_API_BASE_URL,
erl_params=ERL_PARAMS,
cwd='./papertrading_erl',
total_timesteps=1e5)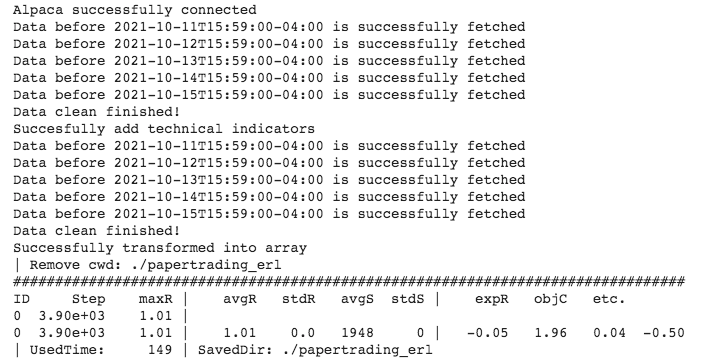
2.4 Test our DRL agent
The purpose of backtesting is to tune model hyperparameters, make sure that we get a positive and valid return/reward (model converges), and get a good performing strategy.
#demo for elegantrl
account_value_erl=
test(start_date = '2021-10-18',
end_date = '2021-10-19',
ticker_list = ticker_list,
data_source = 'alpaca',
time_interval= '1Min',
technical_indicator_list= TECHNICAL_INDICATORS_LIST,
drl_lib='elegantrl',
env=env,
model_name='ppo',
API_KEY = API_KEY,
API_SECRET = API_SECRET,
APCA_API_BASE_URL = APCA_API_BASE_URL,
cwd='./papertrading_erl',
net_dimension = 512)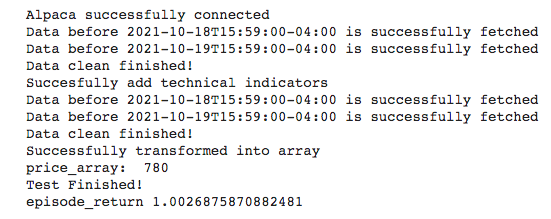
2.5 Use full data to train
After the hyperparameters is fixed, we need to use all data available up to the point to train the model because model needs to dynamically adapt to new patterns in data, in case of concept drift.
#demo for elegantrl
ERL_PARAMS = {"learning_rate": 3e-5,
"batch_size": 2048,
"gamma": 0.99,
"seed":312,
"net_dimension":512}
train(start_date = '2021-10-11',
end_date = '2021-10-19',
ticker_list = ticker_list,
data_source = 'alpaca',
time_interval= '1Min',
technical_indicator_list= TECHNICAL_INDICATORS_LIST,
drl_lib='elegantrl',
env=env,
model_name='ppo',
API_KEY = API_KEY,
API_SECRET = API_SECRET,
APCA_API_BASE_URL = APCA_API_BASE_URL,
erl_params=ERL_PARAMS,
cwd='./papertrading_erl',
total_timesteps=1e5)Part 3: Deploy our DRL Agent to Alpaca Paper Trading API
3.1 Deploy our agent from the saved file
We load the trained DRL model, and connect it to AlpacaPaperTrading environment to start shooting trades.
#demo for elegantrl
paper_trading_erl =
AlpacaPaperTrading(ticker_list = DOW_30_TICKER,
time_interval = '1Min',
drl_lib = 'elegantrl',
agent = 'ppo',
cwd = './papertrading_erl',
net_dim = 512,
state_dim = state_dim,
action_dim= action_dim,
API_KEY = API_KEY,
API_SECRET = API_SECRET,
APCA_API_BASE_URL = APCA_API_BASE_URL,
tech_indicator_list = TECHNICAL_INDICATORS_LIST,
turbulence_thresh=30,
max_stock=1e2)
paper_trading_erl.run()
3.2 Alpaca Paper Trading Environment for Reinforcement Learning
Environment is the key for reinforcement learning, FinRL provides the Alpaca Paper Trading Env, it connects the DRL agent to the Alpaca Trading API and automatically place trades.
- Load agent
- Connect to Alpaca trading API
- Read trading time interval
- Read trading settings
- Initialize account
- Wait for market to open.
- Get DRL states.
- Submit order to place trades.
import datetime
import threading
from finrl.neo_finrl.data_processors.processor_alpaca import AlpacaProcessor
from elegantrl.run import *
import alpaca_trade_api as tradeapi
import time
import pandas as pd
import numpy as np
import torch
import sys
import os
import gym
class AlpacaPaperTrading():
def __init__(self,ticker_list, time_interval, drl_lib, agent, cwd, net_dim,
state_dim, action_dim, API_KEY, API_SECRET,
APCA_API_BASE_URL, tech_indicator_list, turbulence_thresh=30,
max_stock=1e2, latency = None):
#load agent
self.drl_lib = drl_lib
if agent =='ppo':
if drl_lib == 'elegantrl':
from elegantrl.agent import AgentPPO
#load agent
try:
agent = AgentPPO()
agent.init(net_dim, state_dim, action_dim)
agent.save_or_load_agent(cwd=cwd, if_save=False)
self.act = agent.act
self.device = agent.device
except:
raise ValueError('Fail to load agent!')
elif drl_lib == 'rllib':
from ray.rllib.agents import ppo
from ray.rllib.agents.ppo.ppo import PPOTrainer
config = ppo.DEFAULT_CONFIG.copy()
config['env'] = StockEnvEmpty
config["log_level"] = "WARN"
config['env_config'] = {'state_dim':state_dim,
'action_dim':action_dim,}
trainer = PPOTrainer(env=StockEnvEmpty, config=config)
trainer.restore(cwd)
try:
trainer.restore(cwd)
self.agent = trainer
print("Restoring from checkpoint path", cwd)
except:
raise ValueError('Fail to load agent!')
elif drl_lib == 'stable_baselines3':
from stable_baselines3 import PPO
try:
#load agent
self.model = PPO.load(cwd)
print("Successfully load model", cwd)
except:
raise ValueError('Fail to load agent!')
else:
raise ValueError('The DRL library input is NOT supported yet. Please check your input.')
else:
raise ValueError('Agent input is NOT supported yet.')
#connect to Alpaca trading API
try:
self.alpaca = tradeapi.REST(API_KEY,API_SECRET,APCA_API_BASE_URL, 'v2')
except:
raise ValueError('Fail to connect Alpaca. Please check account info and internet connection.')
#read trading time interval
if time_interval == '1s':
self.time_interval = 1
elif time_interval == '5s':
self.time_interval = 5
elif time_interval == '1Min':
self.time_interval = 60
elif time_interval == '5Min':
self.time_interval = 60 * 5
elif time_interval == '15Min':
self.time_interval = 60 * 15
else:
raise ValueError('Time interval input is NOT supported yet.')
#read trading settings
self.tech_indicator_list = tech_indicator_list
self.turbulence_thresh = turbulence_thresh
self.max_stock = max_stock
#initialize account
self.stocks = np.asarray([0] * len(ticker_list)) #stocks holding
self.stocks_cd = np.zeros_like(self.stocks)
self.cash = None #cash record
self.stocks_df = pd.DataFrame(self.stocks, columns=['stocks'], index = ticker_list)
self.asset_list = []
self.price = np.asarray([0] * len(ticker_list))
self.stockUniverse = ticker_list
self.turbulence_bool = 0
self.equities = []
def test_latency(self, test_times = 10):
total_time = 0
for i in range(0, test_times):
time0 = time.time()
self.get_state()
time1 = time.time()
temp_time = time1 - time0
total_time += temp_time
latency = total_time/test_times
print('latency for data processing: ', latency)
return latency
def run(self):
orders = self.alpaca.list_orders(status="open")
for order in orders:
self.alpaca.cancel_order(order.id)
# Wait for market to open.
print("Waiting for market to open...")
tAMO = threading.Thread(target=self.awaitMarketOpen)
tAMO.start()
tAMO.join()
print("Market opened.")
while True:
# Figure out when the market will close so we can prepare to sell beforehand.
clock = self.alpaca.get_clock()
closingTime = clock.next_close.replace(tzinfo=datetime.timezone.utc).timestamp()
currTime = clock.timestamp.replace(tzinfo=datetime.timezone.utc).timestamp()
self.timeToClose = closingTime - currTime
if(self.timeToClose < (60)):
# Close all positions when 1 minutes til market close.
print("Market closing soon. Stop trading.")
break
'''# Close all positions when 1 minutes til market close.
print("Market closing soon. Closing positions.")
positions = self.alpaca.list_positions()
for position in positions:
if(position.side == 'long'):
orderSide = 'sell'
else:
orderSide = 'buy'
qty = abs(int(float(position.qty)))
respSO = []
tSubmitOrder = threading.Thread(target=self.submitOrder(qty, position.symbol, orderSide, respSO))
tSubmitOrder.start()
tSubmitOrder.join()
# Run script again after market close for next trading day.
print("Sleeping until market close (15 minutes).")
time.sleep(60 * 15)'''
else:
trade = threading.Thread(target=self.trade)
trade.start()
trade.join()
last_equity = float(self.alpaca.get_account().last_equity)
cur_time = time.time()
self.equities.append([cur_time,last_equity])
time.sleep(self.time_interval)
def awaitMarketOpen(self):
isOpen = self.alpaca.get_clock().is_open
while(not isOpen):
clock = self.alpaca.get_clock()
openingTime = clock.next_open.replace(tzinfo=datetime.timezone.utc).timestamp()
currTime = clock.timestamp.replace(tzinfo=datetime.timezone.utc).timestamp()
timeToOpen = int((openingTime - currTime) / 60)
print(str(timeToOpen) + " minutes til market open.")
time.sleep(60)
isOpen = self.alpaca.get_clock().is_open
def trade(self):
state = self.get_state()
if self.drl_lib == 'elegantrl':
with torch.no_grad():
s_tensor = torch.as_tensor((state,), device=self.device)
a_tensor = self.act(s_tensor)
action = a_tensor.detach().cpu().numpy()[0]
action = (action * self.max_stock).astype(int)
elif self.drl_lib == 'rllib':
action = self.agent.compute_single_action(state)
elif self.drl_lib == 'stable_baselines3':
action = self.model.predict(state)[0]
else:
raise ValueError('The DRL library input is NOT supported yet. Please check your input.')
self.stocks_cd += 1
if self.turbulence_bool == 0:
min_action = 10 # stock_cd
for index in np.where(action < -min_action)[0]: # sell_index:
sell_num_shares = min(self.stocks[index], -action[index])
qty = abs(int(sell_num_shares))
respSO = []
tSubmitOrder = threading.Thread(target=self.submitOrder(qty, self.stockUniverse[index], 'sell', respSO))
tSubmitOrder.start()
tSubmitOrder.join()
self.cash = float(self.alpaca.get_account().cash)
self.stocks_cd[index] = 0
for index in np.where(action > min_action)[0]: # buy_index:
if self.cash < 0:
tmp_cash = 0
else:
tmp_cash = self.cash
buy_num_shares = min(tmp_cash // self.price[index], abs(int(action[index])))
qty = abs(int(buy_num_shares))
respSO = []
tSubmitOrder = threading.Thread(target=self.submitOrder(qty, self.stockUniverse[index], 'buy', respSO))
tSubmitOrder.start()
tSubmitOrder.join()
self.cash = float(self.alpaca.get_account().cash)
self.stocks_cd[index] = 0
else: # sell all when turbulence
positions = self.alpaca.list_positions()
for position in positions:
if(position.side == 'long'):
orderSide = 'sell'
else:
orderSide = 'buy'
qty = abs(int(float(position.qty)))
respSO = []
tSubmitOrder = threading.Thread(target=self.submitOrder(qty, position.symbol, orderSide, respSO))
tSubmitOrder.start()
tSubmitOrder.join()
self.stocks_cd[:] = 0
def get_state(self):
alpaca = AlpacaProcessor(api=self.alpaca)
price, tech, turbulence = alpaca.fetch_latest_data(ticker_list = self.stockUniverse, time_interval='1Min',
tech_indicator_list=self.tech_indicator_list)
turbulence_bool = 1 if turbulence >= self.turbulence_thresh else 0
turbulence = (self.sigmoid_sign(turbulence, self.turbulence_thresh) * 2 ** -5).astype(np.float32)
tech = tech * 2 ** -7
positions = self.alpaca.list_positions()
stocks = [0] * len(self.stockUniverse)
for position in positions:
ind = self.stockUniverse.index(position.symbol)
stocks[ind] = ( abs(int(float(position.qty))))
stocks = np.asarray(stocks, dtype = float)
cash = float(self.alpaca.get_account().cash)
self.cash = cash
self.stocks = stocks
self.turbulence_bool = turbulence_bool
self.price = price
amount = np.array(max(self.cash, 1e4) * (2 ** -12), dtype=np.float32)
scale = np.array(2 ** -6, dtype=np.float32)
state = np.hstack((amount,
turbulence,
self.turbulence_bool,
price * scale,
self.stocks * scale,
self.stocks_cd,
tech,
)).astype(np.float32)
print(len(self.stockUniverse))
return state
def submitOrder(self, qty, stock, side, resp):
if(qty > 0):
try:
self.alpaca.submit_order(stock, qty, side, "market", "day")
print("Market order of | " + str(qty) + " " + stock + " " + side + " | completed.")
resp.append(True)
except:
print("Order of | " + str(qty) + " " + stock + " " + side + " | did not go through.")
resp.append(False)
else:
print("Quantity is 0, order of | " + str(qty) + " " + stock + " " + side + " | not completed.")
resp.append(True)
@staticmethod
def sigmoid_sign(ary, thresh):
def sigmoid(x):
return 1 / (1 + np.exp(-x * np.e)) - 0.5
return sigmoid(ary / thresh) * thresh
class StockEnvEmpty(gym.Env):
#Empty Env used for loading rllib agent
def __init__(self,config):
state_dim = config['state_dim']
action_dim = config['action_dim']
self.observation_space = gym.spaces.Box(low=-3000, high=3000, shape=(state_dim,), dtype=np.float32)
self.action_space = gym.spaces.Box(low=-1, high=1, shape=(action_dim,), dtype=np.float32)
def reset(self):
return
def step(self, actions):
returnPart 4: Check Portfolio Performance
We can see the trading performance such as portfolio value, PnL, order history directly from the Alpaca paper trading interface.
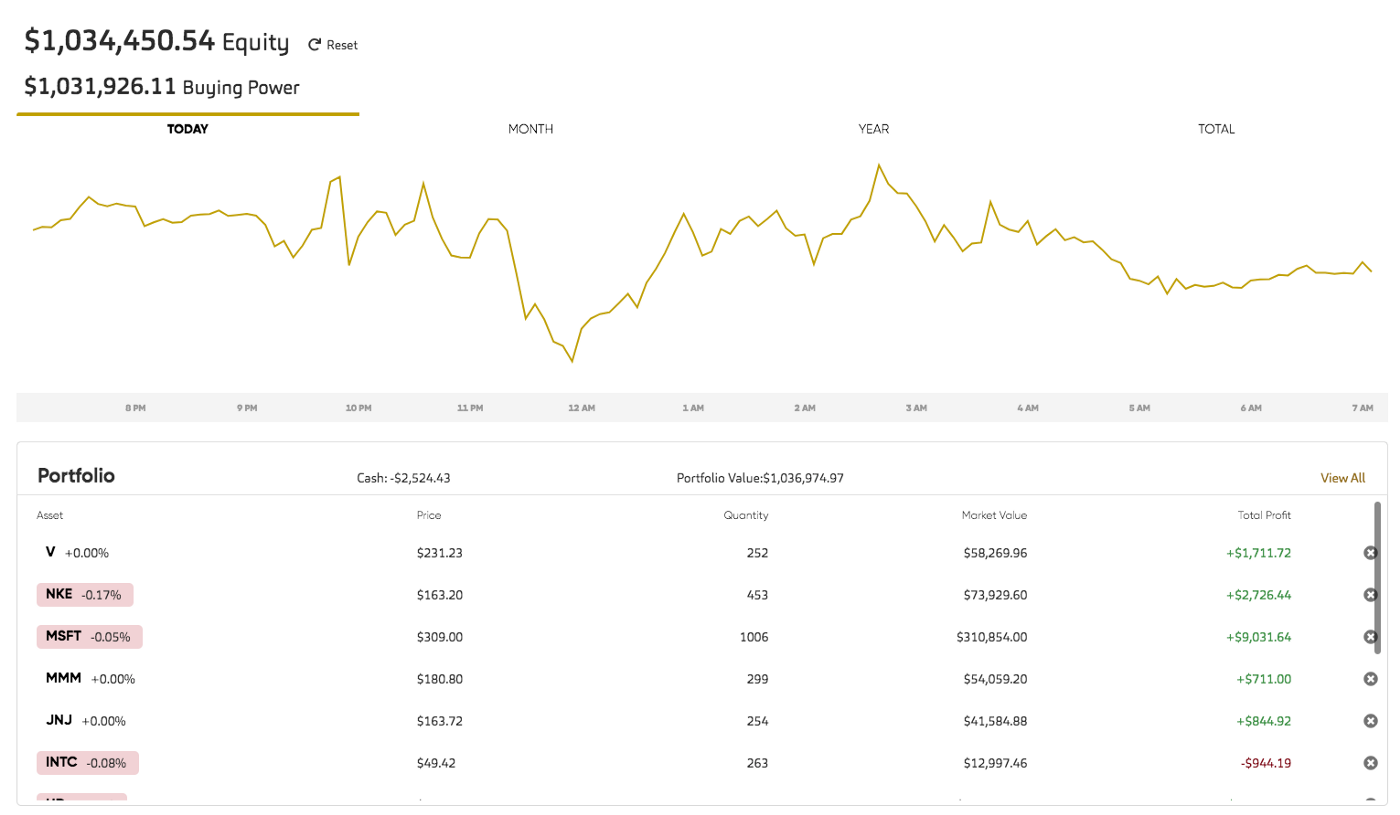
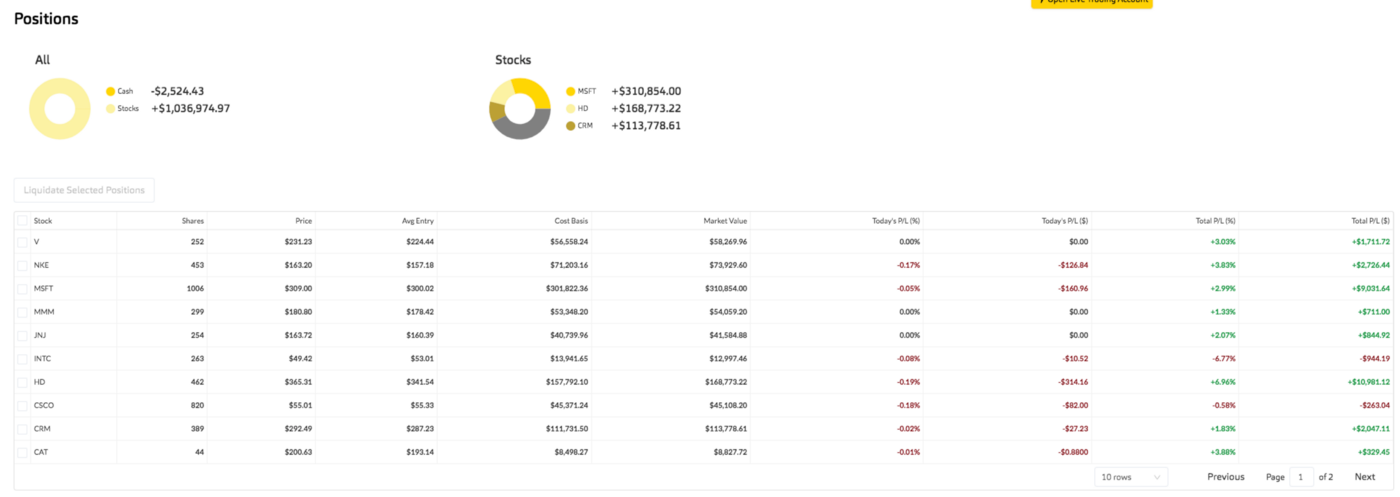
FinRL also plots cumulative return by calling the Alpaca API to get portfolio history.
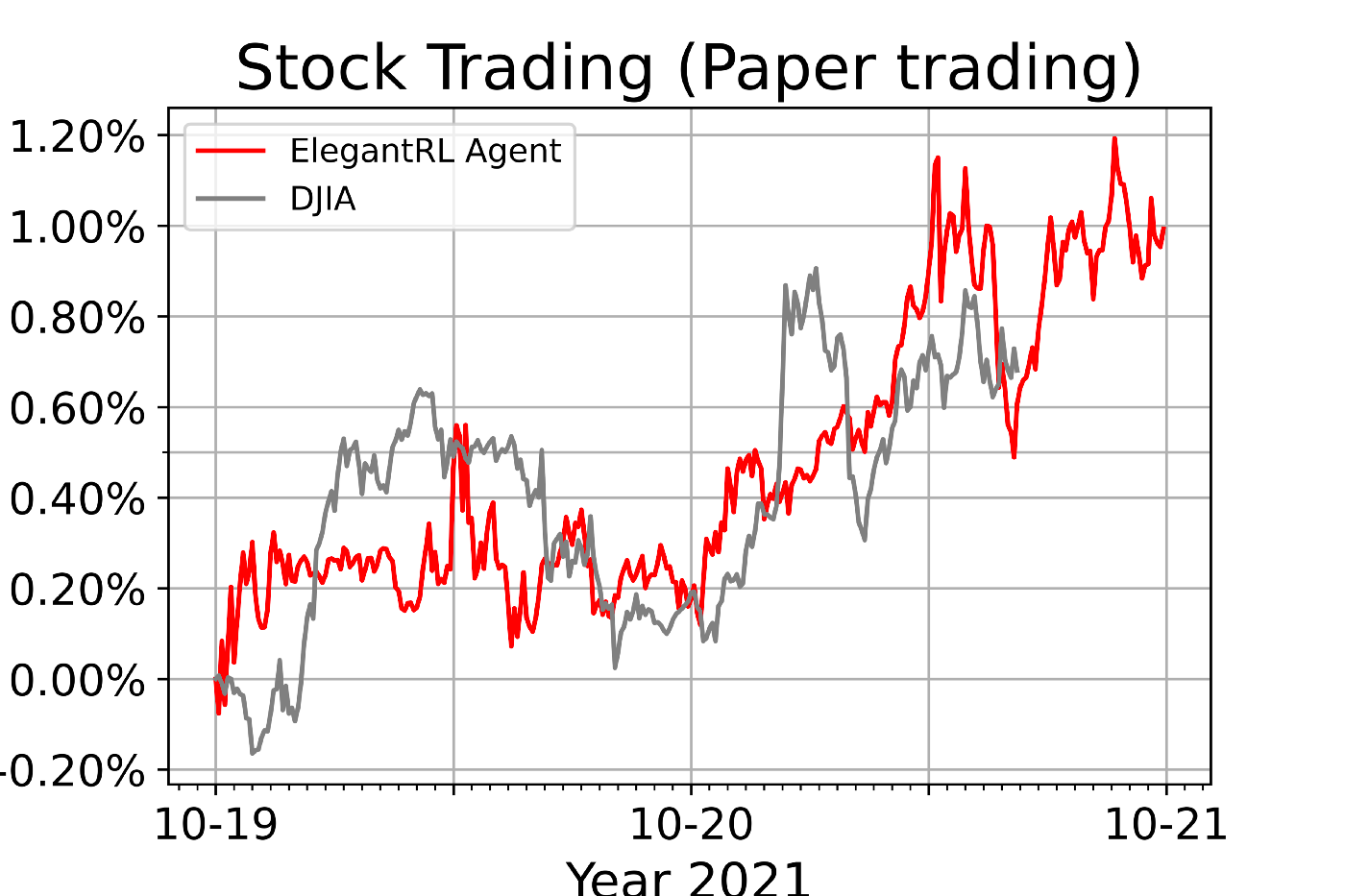
Conclusions
We discussed the step-by-step instructions to deploy a deep reinforcement learning agent to Alpaca paper trading API. In future blogs, we’ll dive deeper into the DRL training and hyperparameter tuning part. Happy trading!
Please report any issues to our Github.
The Paper Trading API is offered by AlpacaDB, Inc. and does not require real money or permit a user to transact in real securities in the market. Providing use of the Paper Trading API is not an offer or solicitation to buy or sell securities, securities derivative or futures products of any kind, or any type of trading or investment advice, recommendation or strategy, given or in any manner endorsed by AlpacaDB, Inc. or any AlpacaDB, Inc. affiliate and the information made available through the Paper Trading API is not an offer or solicitation of any kind in any jurisdiction where AlpacaDB, Inc. or any AlpacaDB, Inc. affiliate is not authorized to do business.
Alpaca does not prepare, edit, or endorse Third Party Content. Alpaca does not guarantee the accuracy, timeliness, completeness or usefulness of Third Party Content, and is not responsible or liable for any content, advertising, products, or other materials on or available from third party sites.
Brokerage services are provided by Alpaca Securities LLC ("Alpaca"), member FINRA/SIPC, a wholly-owned subsidiary of AlpacaDB, Inc. Technology and services are offered by AlpacaDB, Inc.




